背景¶
Facebook的数据仓库存储在少量大型Hadoop/HDFS集群。Hive是Facebook在几年前专为Hadoop打造的一款数据仓库工具。在以前,Facebook的科学家和分析师一直依靠Hive来做数据分析。但Hive使用MapReduce作为底层计算框架,是专为批处理设计的。但随着数据越来越多,使用Hive进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求。Facebook也调研了其他比Hive更快的工具,但它们要么在功能有所限制要么就太简单,以至于无法操作Facebook庞大的数据仓库。
2012年开始试用的一些外部项目都不合适,他们决定自己开发,这就是Presto。2012年秋季开始开发,目前该项目已经在超过 1000名Facebook雇员中使用,运行超过30000个查询,每日数据在1PB级别。Facebook称Presto的性能比Hive要好上10倍多。2013年Facebook正式宣布开源Presto。
流程¶
数据仓库¶
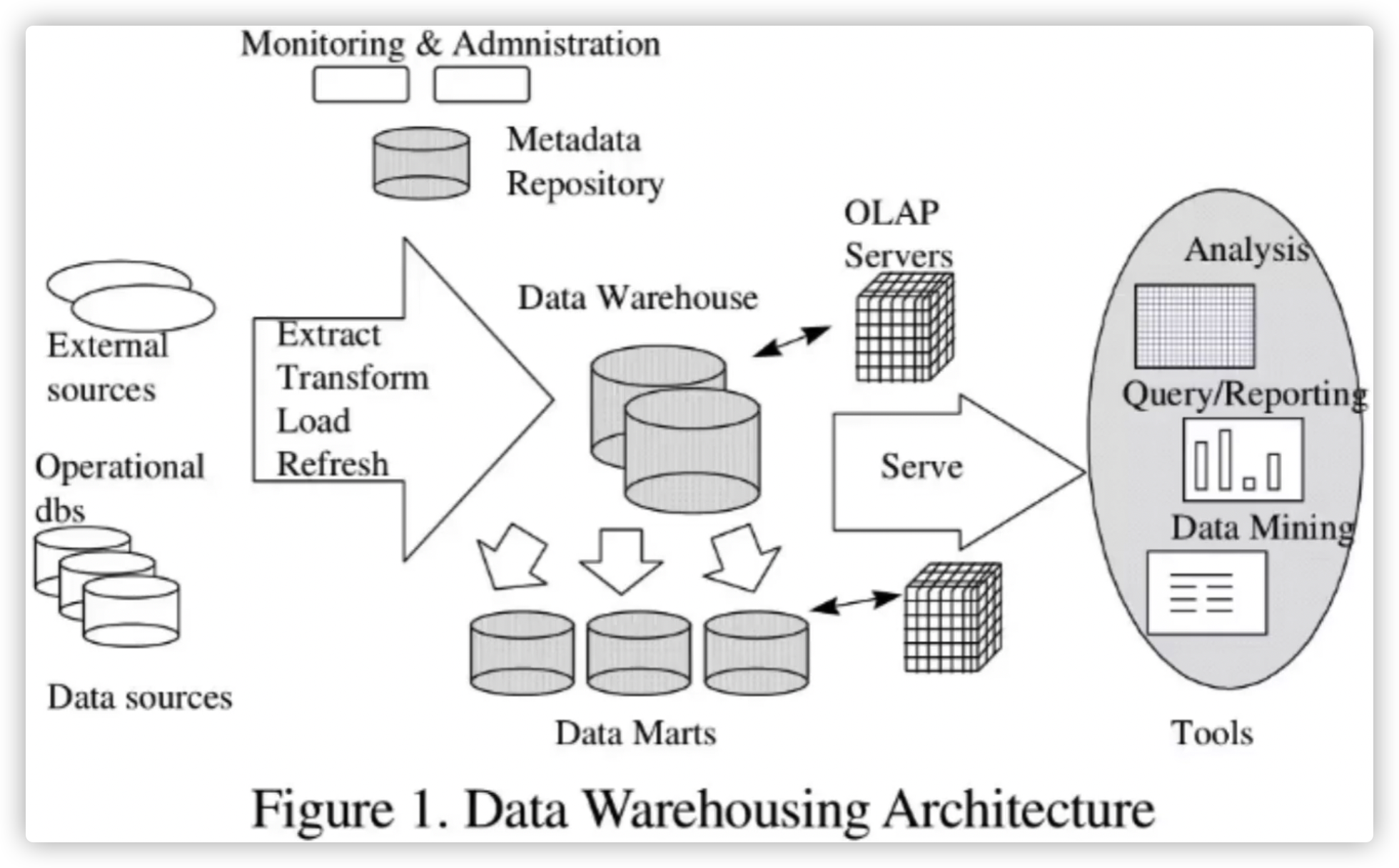
数据仓库指的是将多个数据源的数据经过ETL处理之后,按照一定的主题集成起来提供决策支持和联机分析应用的结构化数据环境。
ETL指的是Extract、Transform、Load。
下图是大致的数据处理示意图:
Hive¶
Hive是给予Hadoop的数据仓库工具,提供类sql语法。
Hive是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库中。
以MR作为计算引擎、HDFS作为存储系统,提供超大数据集的计算、扩展能力。
Hive数据存储:Hive的数据是存储在HDFS上的,Hive表和库是对HDFS上数据的映射。
Hive元数据存储:元数据存储一般在外部关系库(Mysql),与Presto、Impala等共享。
Hive语句的执行过程:将HQL转化为MapReduce任务运行。因为你MR过程中会涉及到大量的IO操作,导致速度比较慢。
Presto架构¶
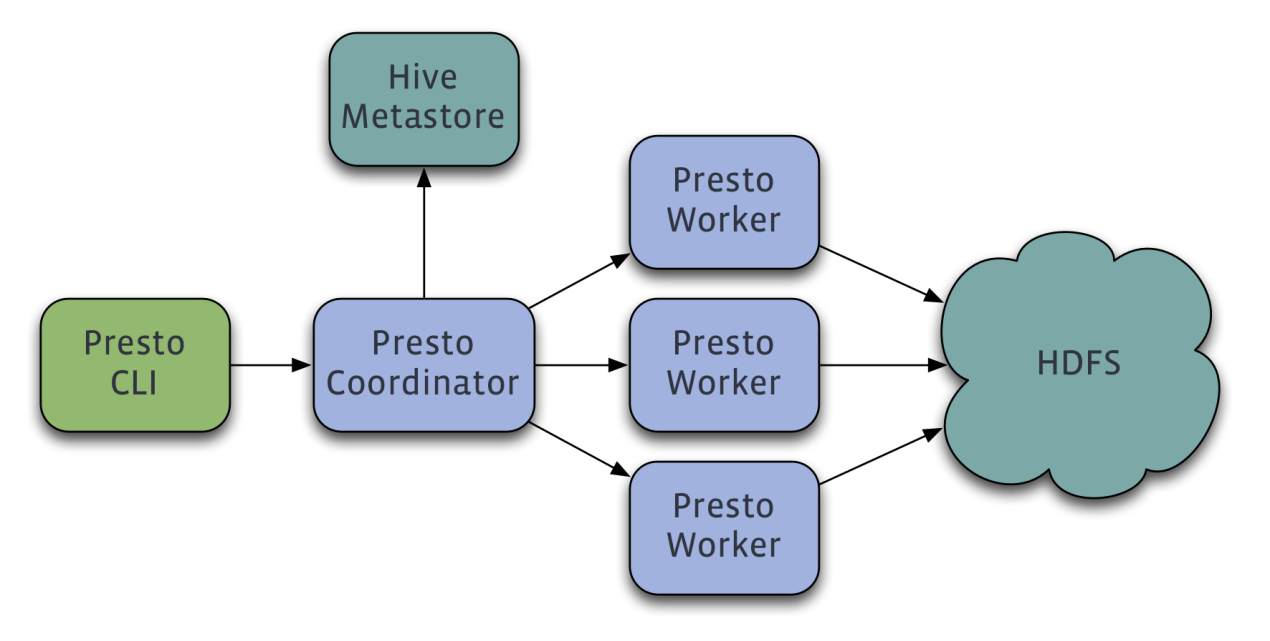
Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
Presto查询过程¶
相较于传统的SQL优化原理之外,Presto采用了一些不同的优化方法:
- 完全基于内存的并行计算
- 流水线
- 本地化计算
- 动态编译执行计划
- 小心使用内存和数据结构
- 类BlinkDB的近似查询
- GC控制
以下介绍下Presto查询过程
提交查询¶
用户使用Presto Cli提交一个查询语句后,Cli使用HTTP协议与Coordinator通信,Coordinator收到查询请求后调用SqlParser解析SQL语句得到Statement对象,并将Statement封装成一个QueryStarter对象放入线程池中等待执行。
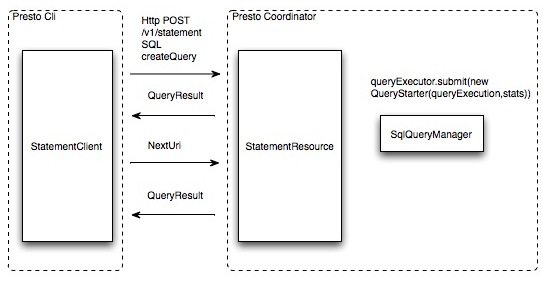
SQL编译¶
Presto与Hive一样,使用Antlr编写SQL语法,语法规则定义在Statement.g和StatementBuilder.g两个文件中。 如下图中所示从SQL编译为最终的物理执行计划大概分为5部,最终生成在每个Worker节点上运行的LocalExecutionPlan,这里不详细介绍SQL解析为逻辑执行计划的过程,通过一个SQL语句来理解查询计划生成之后的计算过程。

样例SQL:
select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10;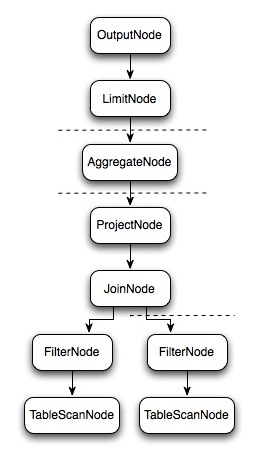
上面的SQL语句生成的逻辑执行计划Plan如上图所示。那么Presto是如何对上面的逻辑执行计划进行拆分以较高的并行度去执行完这个计划呢,我们来看看物理执行计划。
物理执行计划¶
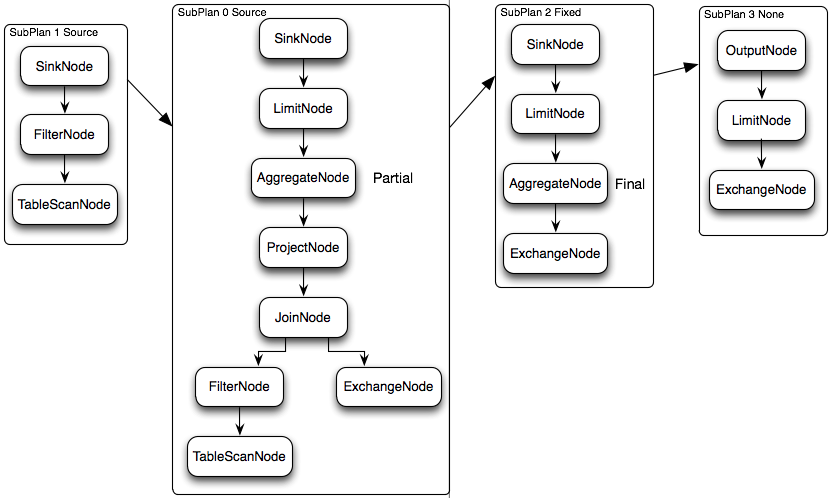
逻辑执行计划图中的虚线就是Presto对逻辑执行计划的切分点,逻辑计划Plan生成的SubPlan分为四个部分,每一个SubPlan都会提交到一个或者多个Worker节点上执行。
SubPlan有几个重要的属性planDistribution、outputPartitioning、partitionBy属性。
- PlanDistribution表示一个查询Stage的分发方式,逻辑执行计划图中的4个SubPlan共有3种不同的PlanDistribution方式:Source表示这个SubPlan是数据源,Source类型的任务会按照数据源大小确定分配多少个节点进行执行;Fixed表示这个SubPlan会分配固定的节点数进行执行(Config配置中的query.initial-hash-partitions参数配置,默认是8);None表示这个SubPlan只分配到一个节点进行执行。在下面的执行计划中,SubPlan1和SubPlan0 PlanDistribution=Source,这两个SubPlan都是提供数据源的节点,SubPlan1所有节点的读取数据都会发向SubPlan0的每一个节点;SubPlan2分配8个节点执行最终的聚合操作;SubPlan3只负责输出最后计算完成的数据。
- OutputPartitioning属性只有两个值HASH和NONE,表示这个SubPlan的输出是否按照partitionBy的key值对数据进行Shuffle。在下面的执行计划中只有SubPlan0的OutputPartitioning=HASH,所以SubPlan2接收到的数据是按照rank字段Partition后的数据。
参考文献¶
-
SlideShare两个分享Presto的PPT
-
美团技术团队,Presto实现原理和美团的使用实践,2014



