简述¶
Spark提供了一种称为RDD(resilient distributed dataset,弹性分布式数据集)的简单逻辑数据结,是Spark最基本的抽象。DataFrame和DataSet都是基于RDD构建的。RDD操作分为转化操作和行为操作。
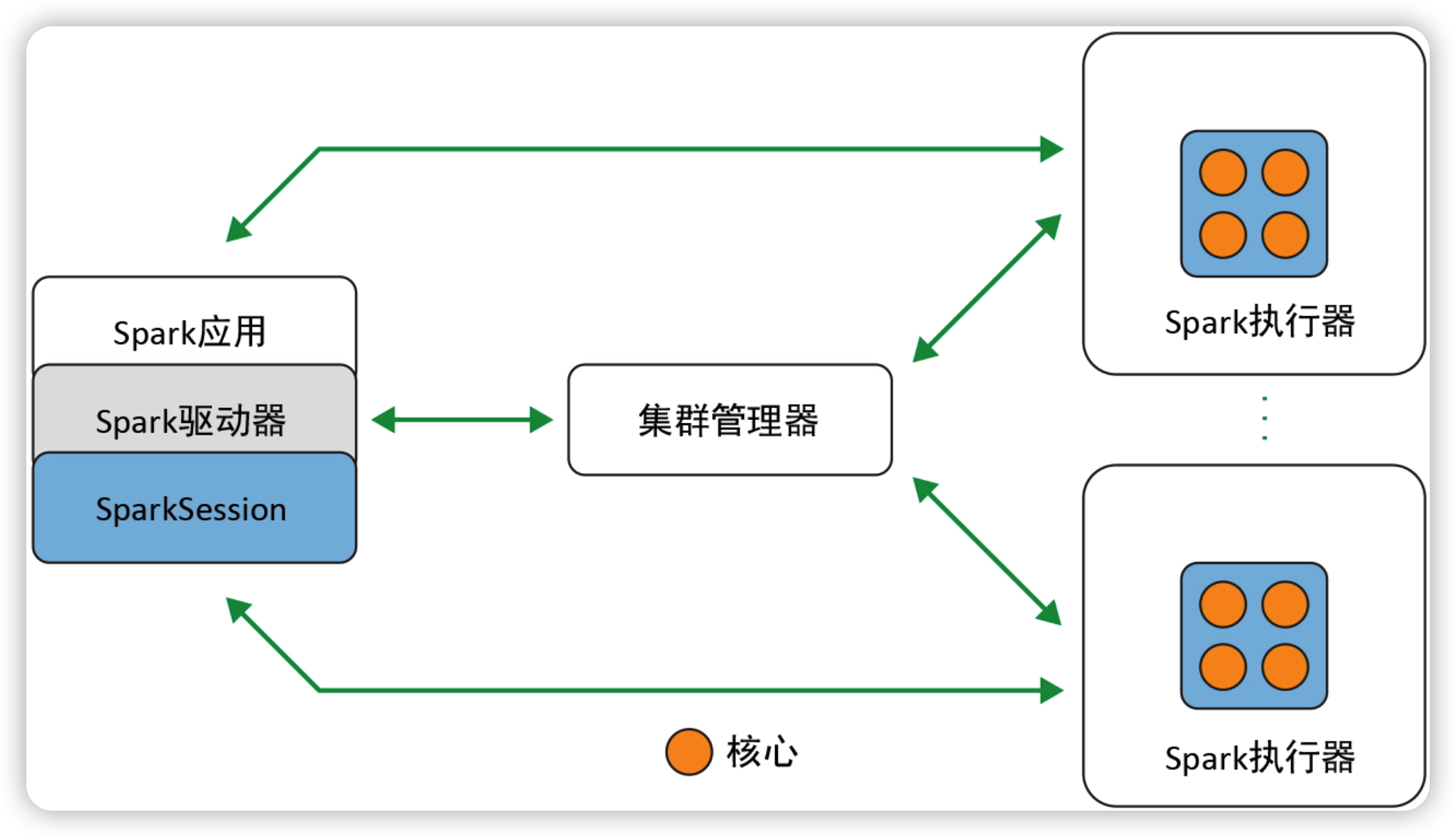
上图为Spark的组件和架构。
Spark驱动器¶
负责初始化SparkSession。
- 与集群管理器打交道
- 向集群管理器申请Spark执行器(JVM)所需要的资源
- 将所有的Spark操作转化为DAG计算,并负责调度,将计算任务分发至Spark执行器上。
一旦资源分配完成,创建好执行器后,驱动器就会直接与执行器通信。
SparkSession¶
在Spark2.0中,SparkSession是所有Spark操作和数据的统一入口,可以创建JVM运行时参数、定义DataFrame或DataSet、从数据读取数据、访问数据库元数据,并发起Spark SQL查询。
集群管理器¶
负责管理和分配集群各个节点的资源,以用于Spark应用的执行。
Spark支持四种集群管理器:
- Spark自带的独立集群管理器
- Apache Hadoop YARN
- Apache Mesos
- Kubernetes
Spark执行器¶
在集群内各工作节点上运行。执行器与驱动器程序通信,并负责在工作节点上执行任务。在大多数部署模式中,每个工作节点只有一个执行器。
部署模式¶
| 模式 | Spark驱动器 | Spark执行器 | 集群管理器 |
|---|---|---|---|
| 本地模式 | 在一个JVM上运行 | 与Spark驱动器在同一个JVM中运行 | 在同一台主机上运行 |
| 独立模式 | 在集群内的任意节点上运行 | 集群中的每个节点都会启动自己的执行器JVM | 可能随机分配到集群内的任意主机上 |
| YARM客户端模式 | 在客户端内运行,不属于集群的一部分 | YARN的节点管理器所启动的容器 | YARN的资源管理器与YARN的应用主容器协作,从节点管理器上为执行器分配容器 |
| YARN集群模式 | 在YARN的应用主容器内运行 | YARN的节点管理器所启动的容器 | YARN的资源管理器与YARN的应用主容器协作,从节点管理器上为执行器分配容器 |
| Kubernetes | 在一个Kubernetes pod内执行 | 各个执行器在各自的pod中运行 | Kuvernetes Master |
RDD操作¶
转化操作¶
指的是将Spark DataFrame转化为新的DataFrame而不改变原有数据的操作,都是惰性求值,将具体的转化关系作为血缘记录下来,在后续生成执行计划时重新安排要做的转化操作。
- orderBy
- groupBy
- filterBy
- select
- join
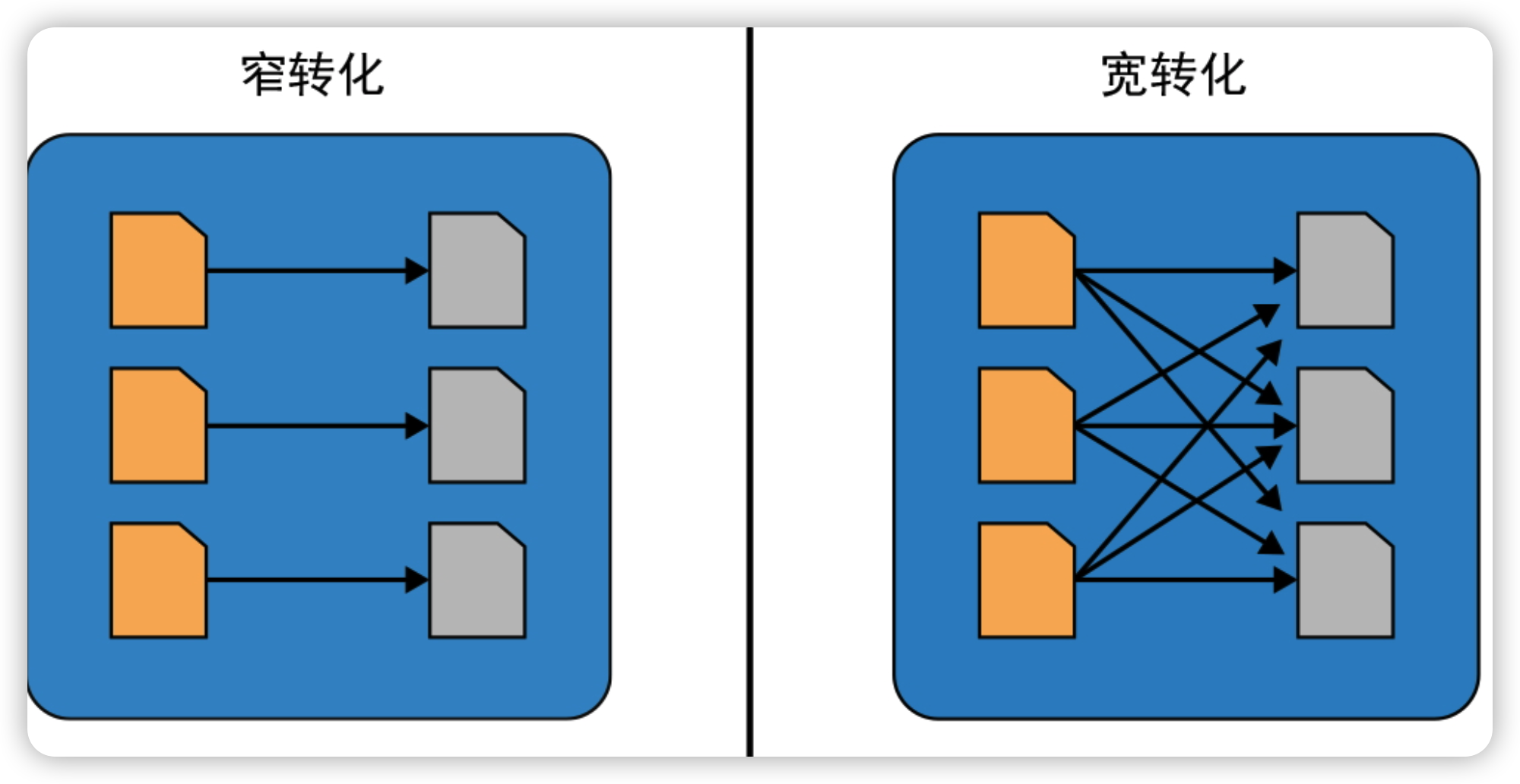
窄转化:在每个数据分区上的操作时独立的,生成输出的数据分区时不需要跨分区交换任何数据。
宽转化:需要从其他分区读取数据并整合
行为操作¶
会触发所记录下的转化操作。
- show
- take
- count
- collect
- save
RDD¶
RDD是Spark最基本的抽象。其主要有三个属性:
- 依赖关系
- 分区(包括一些位置信息)
- 计算函数



