前言¶
这篇博客作为自身阅读论文的一个备忘。记录自己看过的论文中的所见、所思、所感。
前置知识¶
QoS¶
解释:QoS(Quality of Service,服务质量)指一个网络能够利用各种基础技术,为指定的网络通信提供更好的服务能力,是网络的一种安全机制, 是用来解决网络延迟和阻塞等问题的一种技术。QoS的保证对于容量有限的网络来说是十分重要的,特别是对于流多媒体应用,例如VoIP和IPTV等,因为这些应用常常需要固定的传输率,对延时也比较敏感。
定义:当网络发生拥塞的时候,所有的数据流都有可能被丢弃;为满足用户对不同应用不同服务质量的要求,就需要网络能根据用户的要求分配和调度资源,对不同的数据流提供不同的服务质量:对实时性强且重要的数据报文优先处理;对于实时性不强的普通数据报文,提供较低的处理优先级,网络拥塞时甚至丢弃。QoS应运而生。支持QoS功能的设备,能够提供传输品质服务;针对某种类别的数据流,可以为它赋予某个级别的传输优先级,来标识它的相对重要性,并使用设备所提供的各种优先级转发策略、拥塞避免等机制为这些数据流提供特殊的传输服务。配置了QoS的网络环境,增加了网络性能的可预知性,并能够有效地分配网络带宽,更加合理地利用网络资源。
Best-Effort service¶
解释: 标准的因特网服务模式。在网络接口发生拥塞时,不顾及用户或应用,马上丢弃数据包,直到业务量有所减少为止。对Best-Effort服务模型,网络尽最大的可能性来发送报文。但对延时、可靠性等性能不提供任何保证。
Best-Effort服务模型是网络的缺省服务模型,通过FIFO(first in first out 先入先出)队列来实现。它适用于绝大多数网络应用,如FTP、E-Mail等。
Integrated service¶
综合服务模型,简称Int-Serv
Int-Serv是一个综合服务模型,它可以满足多种QoS需求。该模型使用资源预留协议(RSVP),RSVP运行在从源端到目的端的每个设备上,可以监视每个流,以防止其消耗资源过多。这种体系能够明确区分并保证每一个业务流的服务质量,为网络提供最细粒度化的服务质量区分。但是,Inter-Serv模型对设备的要求很高,当网络中的数据流数量很大时,设备的存储和处理能力会遇到很大的压力。Inter-Serv模型可扩展性很差,难以在Internet核心网络实施。
Differentiated service¶
Diff-Serv服务模型是一个多服务模型,它可以满足不同的QoS需求。与Int-Serv不同,它不需要通知网络为每个业务预留资源。区分服务实现简单,扩展性较好。
P、NP、NP-hard、NP-complete¶
最简单的解释: P:算起来很快的问题 NP:算起来不一定快,但对于任何答案我们都可以快速的验证这个答案对不对 NP-hard:比所有的NP问题都难的问题 NP-complete:满足两点:
- 是NP hard的问题
- 是NP问题
P就是能在多项式时间内解决的问题,NP就是能在多项式时间验证答案正确与否的问题。
模拟退火算法¶
模拟退火是一种通用概率算法,常用来在一定时间内寻找在一个很大搜寻空间中的近似最优解。
模拟退火来自冶金学的专有名词退火。退火是将材料加热后再经特定速率冷却,目的是增大晶粒的体积,并且减少晶格中的缺陷。材料中的原子原来会停留在使内能有局部最小值的位置,加热使能量变大,原子会离开原来位置,而随机在其他位置中移动。退火冷却时速度较慢,使得原子有较多可能可以找到内能比原先更低的位置。
模拟退火的原理也和金属退火的原理近似:我们将热力学的理论套用到统计学上,将搜寻空间内每一点想像成空气内的分子;分子的能量,就是它本身的动能;而搜寻空间内的每一点,也像空气分子一样带有“能量”,以表示该点对命题的合适程度。算法先以搜寻空间内一个任意点作起始:每一步先选择一个“邻居”,然后再计算从现有位置到达“邻居”的概率。
可以证明,模拟退火算法所得解依概率收敛到全局最优解。
遗传算法¶
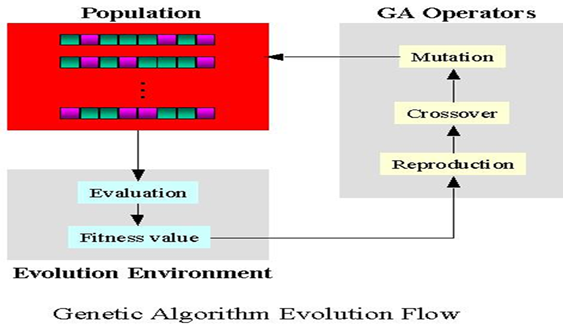
遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。每个个体实际上是染色体(chromosome)带有特征的实体。染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。因此,在一开始需要实现从表现型到基因型的映射即编码工作。由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解。
过程如下:
- 初始化:设置进化代数计数器t=0,设置最大进化代数T,随机生成M个个体作为初始群体P(0)。
- 个体评价:计算群体P(t)中各个个体的适应度。
- 选择运算:将选择算子作用于群体。选择的目的是把优化的个体直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代。选择操作是建立在群体中个体的适应度评估基础上的。
- 交叉运算:将交叉算子作用于群体。遗传算法中起核心作用的就是交叉算子。
- 变异运算:将变异算子作用于群体。即是对群体中的个体串的某些基因座上的基因值作变动。群体P(t)经过选择、交叉、变异运算之后得到下一代群体P(t+1)。
- 终止条件判断:若t=T,则以进化过程中所得到的具有最大适应度个体作为最优解输出,终止计算。
基因型(genotype):性状染色体的内部表现。
表现型(phenotype):染色体决定的性状的外部表现,或者说,根据基因型形成的个体的外部表现。
进化(evolution):种群逐渐适应生存环境,品质不断得到改良。生物的进化是以种群的形式进行的。
适应度(fitness):度量某个物种对于生存环境的适应程度。
选择(selection):以一定的概率从种群中选择若干个个体。一般,选择过程是一种基于适应度的优胜劣汰的过程。
复制(reproduction):细胞分裂时,遗传物质DNA通过复制而转移到新产生的细胞中,新细胞就继承了旧细胞的基因。
交叉(crossover):两个染色体的某一相同位置处DNA被切断,前后两串分别交叉组合形成两个新的染色体。也称基因重组或杂交。
变异(mutation):复制时可能(很小的概率)产生某些复制差错,变异产生新的染色体,表现出新的性状。
w编码(coding):DNA中遗传信息在一个长链上按一定的模式排列。遗传编码可看作从表现型到基因型的映射。
解码(decoding):基因型到表现型的映射。
个体(individual):指染色体带有特征的实体。
种群(population):个体的集合,该集合内个体数称为种群的大小。
Resource allocation algorithms for virtualized service hosting platforms¶
author:Mark Stillwell a , David Schanzenbacha , Frédéric Vivienb , Henri Casanova a,∗
这片论文研究的是在具有多种资源类型的服务器在静态工作量的情况下进行资源分配方案。支持尽力而为和QoS混合场景,通过精确定义的目标函数来提升性能、公平性和集群利用率。
论文的创新点¶
- 定义资源分配问题为静态服务负载,每个服务完全运行在一台VM实例上。这个定义考虑到了多个资源维度。
- 建立了问题的复杂度,并给出混合整数线性函数公式,到达最优的界限。
- 提出几种算法解决问题。
- 模拟评估算法。
- 讨论算法在服务运行在多台服务器上的情况。
问题定义¶
计算机群为同构服务器配有高速网络交换。每个服务包含一个或多个VM实例。每台服务器提供CPU、RAM、I/O、disk。
在第三章,假定每个服务只运行在一台VM实例上。在第六章讨论多VM的服务。
每个服务资源需求量固定。资源分为两类:regid(load-independent)和fluid(load-dependent)
| rigid | fluid |
|---|---|
| 对资源的需求量提供的不能少,多也无法获益 | 对资源的需求量提供的少也能运行,多无法获益 |
取值范围为[0,1]。当有QoS要求时,yield设置一个最低阈值。
假定所有资源的利用率与fluid需求之间呈现线性相关性。
一些没有QoS要求且采用的是尽力而为模式的任务,。
假定所有rigid资源需求都与fluid资源需求无关且彼此独立。
资源份额与响应时间或吞吐量之间的模型在[11],[33],[8],[45],[55],[64],[54]中有定义。这些都只能处理有QoS需求的服务。本论文方法可以处理具有QoS需求的服务和不具有QoS的尽力而为服务。
对于尽力而为服务,yield=scaled yield。yield最小为1时,sclaes yield为1。sclaes yield为负数则资源分配失败。
yield和传统的strtch相比,stretch适用于有时限的任务,而不是连续服务。stretch的定义是作业的流动时间,即作业提交和完成之间的时间,除以该作业在系统中所应达到的流动时间。 最小化最大拉伸被认为是优化平均流动时间的一种方法,同时确保作业不会经历较高的相对流动时间。 因此,这是一种同时优化性能和公平性的方法,而仅使平均拉伸量最小化则容易出现饥饿。
论文使用的是最大化最小yield。
虽然定期迁移可以提高最低收益[56],但是会占用网络资源,具有开销,在本论文不进行考虑。
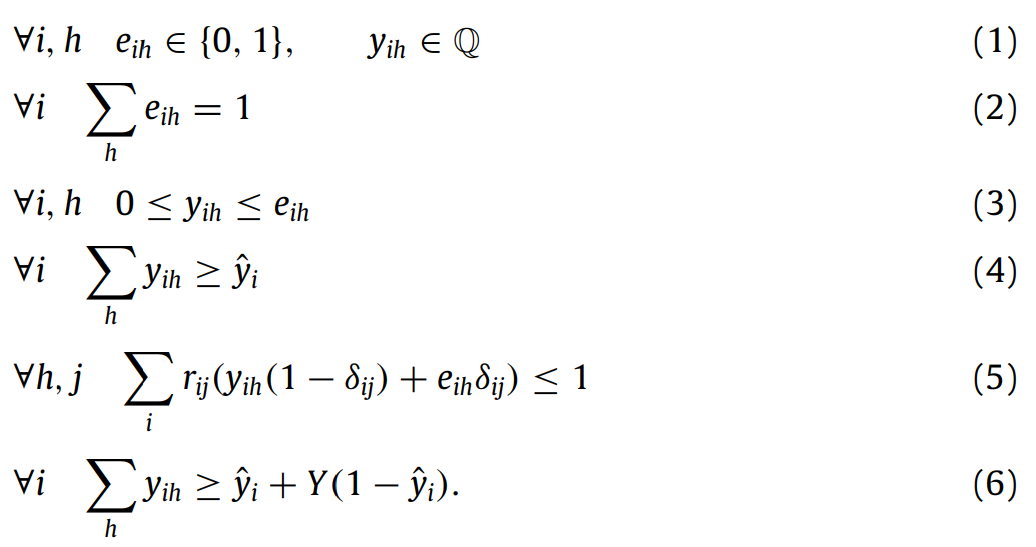
算法¶
贪心算法¶
将服务进行排序。因为在装箱问题中,大多数情况下递增序列效果差于递减序列。所以排序采用递减序列。(S1)随机; (S2)通过递减最大fluid需求进行排序; (S3)通过递减fluid需求的总和; (S4)通过递减最大rigid需求和受约束的fluid需求;(S5)通过递减rigid需求和受约束的fluid需求的总和;(S6)通过递减最大资源需求(无论为fluid还是rigid);(S7)通过递减rigid and fluid 需求。
从七个指标考虑服务器的选择。
遗传算法¶
每个染色体为一个一维数组,索引为服务编号,对应值为服务器编号。
Energy-aware service allocation¶
author:Damien Borgettoa,∗ , Henri Casanova b , Georges Da Costa a , Jean-Marc Piersona
CSL‑driven and energy‑efficient resource scheduling in cloud data center¶
DOI: 10.1007/s11227-019-03036-9
CSL: Customer Satisfaction Level
MSVR:metric based on SLA violation rate
MW:metric based on workload
MRT:metric based on response time
本文创新点¶
- 设计了CSL-driven 高效调度框架以优化云数据中心的能源效率。同时考虑了



