马尔可夫¶
20世纪初,马尔可夫研究自然界有一类事物变化的过程仅与失误的近期状态有关,与事物过去的状态无关.即马尔可夫性.
一个马尔可夫过程是状态间的转移仅依赖前n个状态的过程.这个过程被称为n阶马尔可夫模型,其中n是影响下一个状态的(前)n个状态.
马尔可夫假设:假设模型的当前状态仅仅依赖前面的几个状态.
相关名词¶
- 随机过程的本质就是对一系列随机变量的整体描述.
- 马尔可夫矩阵的性质,其中每个值大于等于0,且每行或者每列和为1(这取决于是左乘还是右乘).
- 马尔可夫的时齐性:从状态i转化到状态j的转义概率
仅仅依赖于时间的长短,与其他(比如起始状态等)均无关.
收敛的必要条件¶
- 可能的状态数是有限的
- 状态间的转移概率需要固定不变
- 从任意状态能够转变到任意状态
- 不能是简单的循环
区别¶
T表示时间空间,E表示状态空间.
- T连续,E连续->连续Markov过程
- T连续,E离散->离散Markov过程
- T离散,E连续->Markov序列
- T离散,E离散->Markov链
转移概率矩阵¶
为马尔可夫链的m步转移矩阵.
马尔可夫预测的核心在于转移概率矩阵的确定,获取方法可以是理论分析亦或实际统计结果给出的,甚至是猜测的.
性质¶
:概率在0~1之间.
- 对于任意的
,
:概率之和为1.
- 对于任意的
,
:不发生转移的概率.
柯尔莫格洛夫-切普曼方程(k-c方程)¶
对于任意的,有
马尔可夫预测¶
- 对于一个马尔可夫链,其一步转移概率矩阵为P.
- 初始状态(初始分布)
,反映了马尔可夫链在初始时候的对于各个状态的概率分布情况,可以搁在一起写个向量
.
- 同样有
,表示经过n步转移后,马尔可夫链对于各个状态的概率分布情况.同样的,把它们搁在一起写成一个向量:
- 预测方法:
收敛到一个固定的向量,称之为马尔可夫链或转移矩阵P的不变分布(不是所有的马尔可夫链都有不变分布).当马尔可夫链有不变分布时,称之为马尔科夫链具有遍历性.
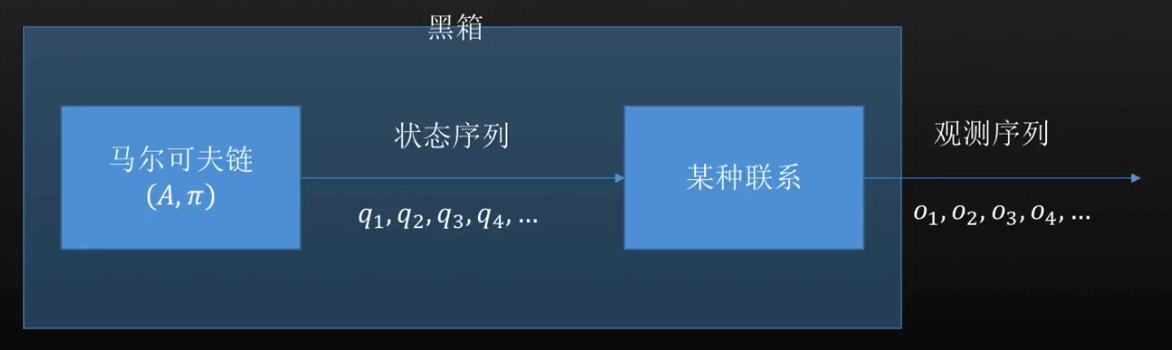
可观测马尔可夫模型¶
对于一个问题而言,我们有初始分布,转移概率矩阵A,在给定的任意一个时刻t,我们都能有一个状态
,时间的变化,随一个状态转移到另一个状态,便能得到一个观测序列,即为状态序列
.且整个问题中一共有n个观测状态.出现这样的序列的概率是:
,所以一个可观测的马尔可夫模型由一个三元组描述:
,一般情况下简记为
.
如果穷举了所有的观测序列:
隐马尔可夫模型¶
两个基本假设¶
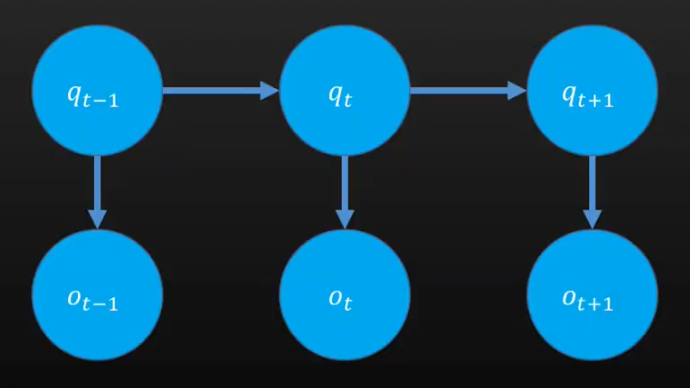
- 齐次马尔可夫性假设:
.表示任意时刻t的状态只依赖前一时刻的状态,与其他状态和观测都无关.
- 观测独立性假设:
.对于任意时刻的观测,只依赖该时刻的状态,与其他时刻的观测和状态都无关.
基本想法¶
系统的状态S无法预测,但是可以观测到某个其他和状态相关联的事物,这个事物出现是伴随系统状态而出现的.
基本假设¶
观测概率不依赖时间(马尔可夫过程)
- 观测集合:
- 观测序列:
- 状态集合:
- 状态序列:
- 观测概率:
,记
,叫做发射概率矩阵
- 隐马尔可夫模型由一个五元组描述
,简记为
.初始分布属于状态集合.
基本问题¶
-
估计:已知模型
解决方法:前向后向算法
-
预测:已知模型
解决方法:Viterbi算法
-
学习:已知一组观测序列,求模型
解决方法:Baum-Welch算法
注意¶
- 不同的状态序列可以产生相同的观测序列(以不同的概率产生)
- 状态转移是随机的,系统在一个状态中产生的观测也随机的
- 可观测的马尔可夫模型是特殊的隐马尔可夫模型
吸收马尔可夫链¶
在马尔可夫链中,称的状态是吸收状态.如果一个马尔可夫链中至少包含一个吸收状态,并且从每一个非吸收状态出发,都能到达某个吸收状态,那么这个马尔科夫链称为吸收马尔可夫链.

对于吸收链P的标准形式,矩阵I-Q具有可逆矩阵N,且。N的元素nij是从非吸收状态
到另一非吸收状态
的平均转移次数。设c为元素全为1的列向量c=[1,1,···,1]',则t=Nc的第i个分量是从第i个非吸收态出发,到某个吸收状态的平均转移次数。从非吸收状态i出发终被吸收状态j吸收的概率由B=NR给出。
详细解释参考:https://www.cnblogs.com/guolei/p/3504931.html
排队论¶
符号表示¶
| 符号 | 说明 |
|---|---|
| X | 顾客到达流或者顾客到达间隔时间的分布 |
| Y | 服务时间的分布 |
| Z | 服务台数目 |
| A | 系统容量限制 |
| B | 顾客源数目 |
| C | 服务规则 |
例如:银行服务系统为先到先服务,C即为FCFS.一般系统容量与顾客源数目均视为无限.指数分布具备无记忆性,即Markov性(M).在这个问题中服务台为1,问题就可以表述为M/M/1.
运行指标¶
- 平均队长
:系统内顾客数的期望(可以理解为在处理的客户和还在等待中的客户)
- 平均排序长
:系统内等待服务的顾客数的期望
- 平均逗留时间
:顾客在系统内逗留时间的期望(可以理解为等待时间+处理时间)
- 平均等待时间
:顾客在排队中等待时间的期望
记号¶
- N(t)表示在时间区间[0,t)内到达的顾客数(t>0)
表示在时间区间[
)内有n个顾客到达的概率.
输入过程¶
-
在不重叠时间区内顾客到达数相互独立;
-
充分小的
时间,在时间区间
内有一个顾客到达的概率与t无关,而大约和区间长
.用
表示单位时间内平均到达的顾客数
-
对于充分小的,在时间区间内有两个或两个以上顾客到达的概率极小,可以忽略,即
符合以上的条件即服从泊松分布.
服务过程¶
- 充分小的
,T为服务时间,用
表示单位时间内平均服务的顾客数.
最大熵¶
克劳德 艾尔伍德 香农在1948年提出信息熵,用来描述信息的不确定程度.
最大熵原理其实就是指包含已知信息(约束条件),不做任何未知假设,把未知事件当成等概率事件处理.
一个系统的信息熵其实是系统中的每一个事件的概率乘上log概率,然后将所有事件相加取复数.
| log底数的取值 | 相应信息熵的单位取值 |
|---|---|
| 2 | 比特(bit) |
| e | 奈特(nat) |
| 10 | 哈托特(hat) |
因为概率总是在0-1之间,log之后小于0,加上负号才是正数.
任务调度算法¶
Conservation BackFilling算法¶
在等待任务队列中选择任务进行回填,该任务必须保证不能使预约在其前面的任务延迟执行。步骤如下:
- 寻找插入点
- 对当前虚拟机的时空分布图进行扫描,如果发现可以满足该任务申请的处理器资源的第一个时间点作为该任务的插入点。
- 从插入点开始,扫描时空图,确保当前任务在插入点后的执行时间处理器都是可用的。
- 若条件2不满足,则返回1继续执行扫描,直到找到一个合适的插入点。
- 更新虚拟机的时空图,及时反馈当前任务的调度情况,将当前任务提交到插入点执行。
Easy BackFilling算法¶
该算法不需要考虑等待队列后面的任务对排在前面任务造成的延迟。回填时根据等待任务申请的处理器资源的大小尽可能提前将小任务回填至空闲资源中执行。在扫描虚拟机时空图前对所有的等待任务按照申请的处理器的资源大小升序排列,优先回填小任务。
Improved BackFilling算法¶
使用Balanced Spiral方法对等待任务进行分类,按照任务所申请的PE的大小进行升序排列,排序处理提交任务所申请的处理器核心数将任务排成V字形的趋势进行排序,然后对后续提交的任务进行回填作业。
Tip¶
显著性水平¶
假设检验是围绕对原假设内容的审定而展开的。如果原假设正确我们接受了(同时也就拒绝了备择假设),或原假设错误我们拒绝了(同时也就接受了备择假设),这表明我们作出了正确的决定。但是,由于假设检验是根据样本提供的信息进行推断的,也就有犯错误的可能。有这样一种情况,原假设正确,而我们却把它当成错误的加以拒绝。犯这种错误的概率用α表示,统计上把α称为假设检验中的显著性水平 ,也就是决策中所面临的风险。
小概率原理¶
小概率原理是指一个事件的发生概率很小,那么它在一次试验中是几乎不可能发生的,但在多次重复试验中是必然发生的。统计学上,把小概率事件在一次实验中看成是实际不可能发生的事件,一般认为等于或小于0.05或0.01的概率为小概率。
离散程度指标¶
离散指标的数据越小,说明数据的离散程度越小,反之亦然.
全距(Range)¶
又称极差,指数据中最大值与最小值的差.即.是一个比较粗糙的测度指标。如果需要全面、精确地说明数据离散程度时,就不宜使用全距.
平均差(Mean Absolute Deviation)¶
各项数值与其均值绝对值之和的平均数,即
虽然平均差简单易懂,但因为使用了绝对值,不便于进一步计算,所以在实际应用中不如其他离散指标应用那样广泛。但在预测领域,还常常使用该指标用于误差的说明。
方差(Variance)¶
指全部数据离差平方的平均数,即.
方差克服了平均差绝对值的问题,成为描述离散程度的一个重要指标。但是,在方差数值含义的解释上却遇到困难。因为方差的单位是数据单位的平方,夸大了数据的离散程度,使人不易直观理解数值意义.
标准差(Standard Deviation)¶
通常取方差的算数平方根作为描述离散程度的指标,即.
样本的方差和标准差¶
分别用表示.与总体的方差和标准差之间的唯一区别就是分数的分母是n-1,而不是n了.因为样本的方差和标准差在使用中,经常作为总体方差和标准差的估计量,如果直接除以样本容量n,得到的结果相对于总体方差和标准差来说是有偏的;除以自由度n-1可以得到总体方差和标准差的较好的估计量。
离散系数(Coefficient Of Variation)¶
为标准差与均值的比值.一般用V表示.总体的离散系数.样本的离散系数
.
异众比率¶
异众比率指的是总体中非众数次数与总体全部次数之比,常常使用来表示.假设有N个样本值,样本存在一个众数c,且众数的个数为n,则异众比率
.
四分位距(interquartile range, IQR)¶
又称四分差,以确定第三四分位数(上分位数)和第一二分位数(下分位数)的区别..用来画出箱线图查看数据的异常点,数据的偏态和数据的大致形状.
四分位数¶
- 第一四分位数
,又称较小四分位数,等于该样本中所有数值由小到大排列后第25%的数字。
- 第二四分位数
,又称中位数,等于该样本中所有数值由小到大排列后第50%的数字。
- 第三四分位数
,又称较大四分位数,等于该样本中所有数值由小到大排列后第75%的数字。
主要选择四分位的百分比值p,及样本总量n.有以下数学公式可以表示:
-
情况1:如果L是一个整数,则取第L和第L+1的平均值.
-
情况2:如果L不是一个整数,则取向下取整.
四分位差(QD)¶
.



